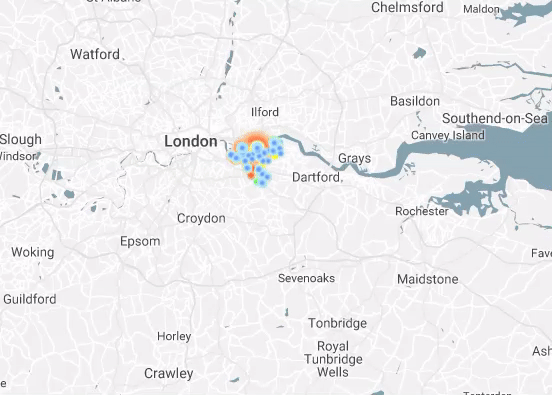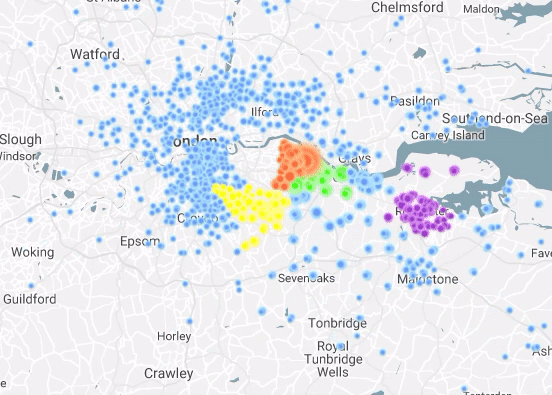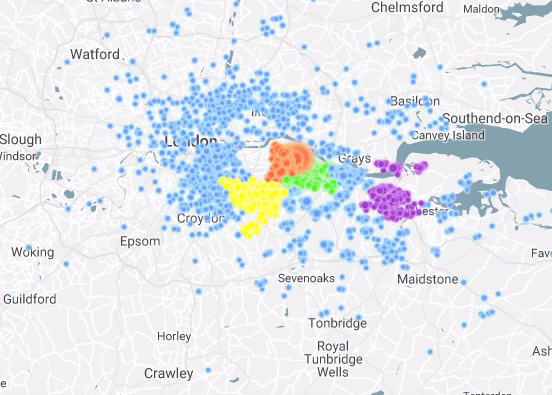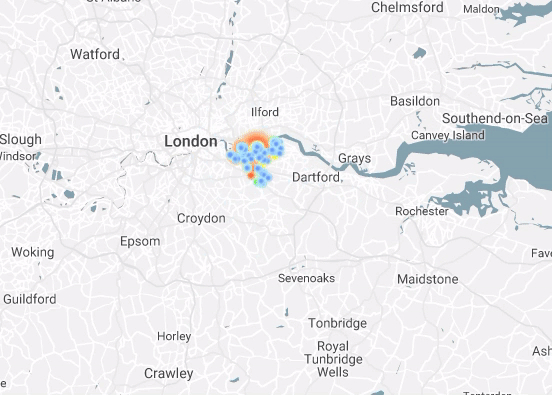
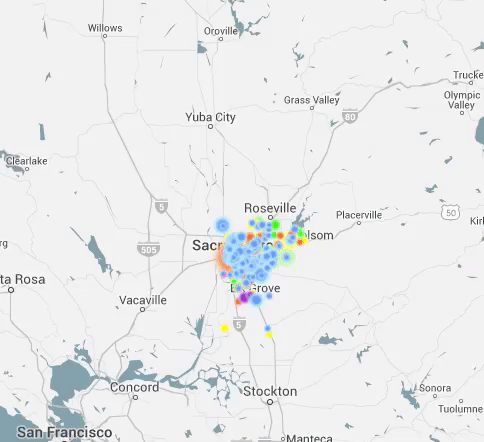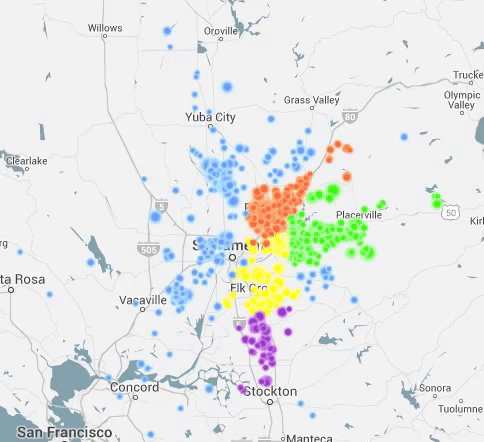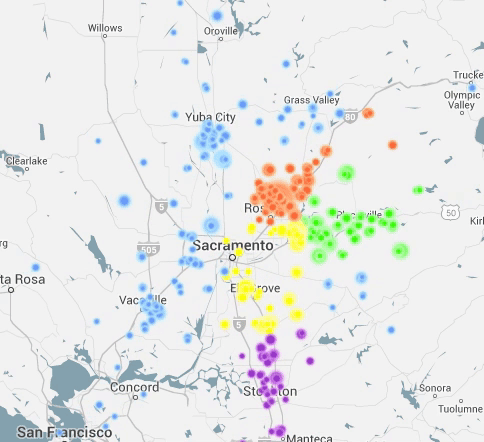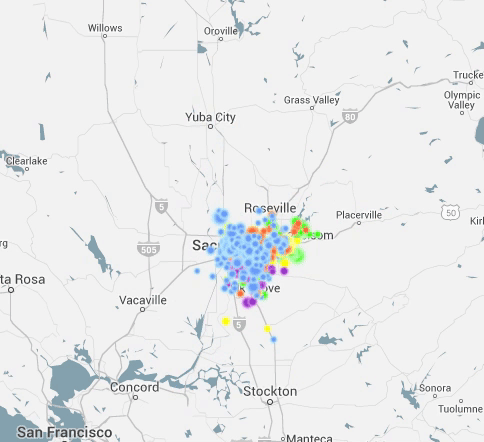
I Have Seen the Light (Through the Cloud)
It’s been a long time since I posted on this blog. That’s mainly because I got a real job which has both kept me pretty busy and partly because I cannot just blithely share the things I work on now like I used to. I started working in the role of what I eventually realized was a data engineer. To be honest, I’m not even sure I knew what a data engineer was before the title was bestowed upon me,…